
Image: Indian National Young Academy of Sciences (INYAS), India, 2021-08-13. Open Science Principles and Practice, slide 38. Peter Murray-Rust, Ayush Garg and Shweata N. Hegde. CC BY 4.0.
By Shweata N. Hegde and CEVOpen community. Hashtag: #cevopen
CEVOpen is an open research project developing open-source tools to enable search tools for Open Access repositories. The project has a prototype tooling that can enable ‘search configurations’ to search large quantities of open research literature—for example speeding up literature reviews. CEVOpen is looking for other research groups who would like to make use of its technology and explore scientific literature to tackle global challenges.
CEVOpen came about as a collaboration from a number of overlapping groups whose “common domain is open knowledge for Phytochemistry” but the technology can be applied to most other topics. The founding members are:
ContentMine a non-profit from Peter Murray-Rust,
EssoilDB lead by Gitanjali Yadav which is a database of essential oils, and
Verriclear, Emanuel Faria’s company which uses essential oils for skincare.
The context: Scientific literature deluge
There are approximately 10,000 scientific papers published every day, approximately. As with COVID and other viral epidemics, we also face many other global challenges that have solutions hidden in the literature. With the scientific output growing by over five papers every minute, how can researchers—let alone citizens—make sense of it?
To give a context for how huge the scientific literature is, let’s imagine a hypothetical situation where you printed out the whole of the scientific literature and stack them up. Can you guess the height the vertical tower of papers would reach? You’d be surprised to know that the scientific paper tower would reach a height greater than that of Mount Everest!
So you can’t read the whole literature! But you normally don’t need to. And there’s an increasing amount of open literature that anyone, anywhere can access—and for practical purposes if it’s not open, it can normally be neglected.
Are we making full use of at least the open literature that’s out there? How can one comprehend—not the whole literature, but at the part that’s of interest? Are we making the best use of the advancing technology to assist in the sense-making process?
In addition, with so much jargon in the literature, how can we make science in English accessible to non-native speakers?
CEVOpen is addressing some of these problems by building Text Data Mining tools.
Text and Data Mining (TDM): ‘The use of automated analytical techniques to analyse text and data for patterns, trends and other useful information.’
– UK Intellectual Property Office (IPO).
CEVOpen tools enable rapid download of literature and help researchers, or any humans, make sense of the downloaded literature. In this blog, we will explore some parts of it in detail.
The components: The use of technology to assist in the sense-making process
CEVOpen has two parts to its TDM software, pygetpapers and ami. There is one other crucial component, Wikidata, that helps us mine and search the literature.
pygetpapers
The first step at mining insights is, pretty obvious, to download the papers. If you’d want 100 papers on the effects of climate change on a given question, say ‘open energy modelling for housing in <insert your city>,’ you wouldn’t be individually downloading these papers from a repository.
With pygetpapers, you can:
- specify a supported repository (say EPMC)
- a query to search
- related dictionary to streamline your search results
- number of papers to download (say, 500)
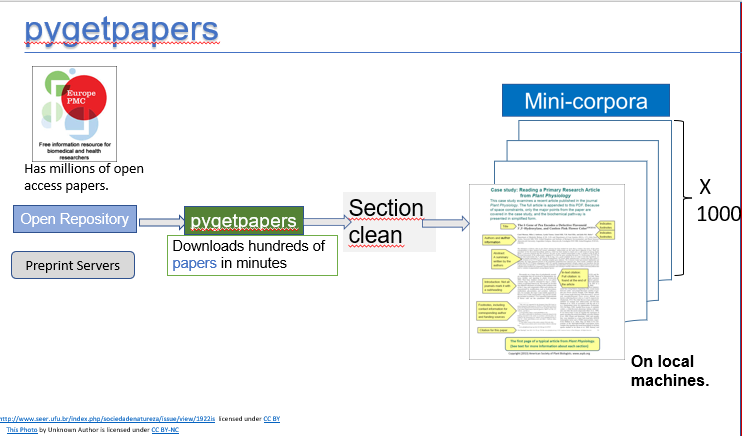
Image: pygetpapers workflow, Shweata N. Hegde, CC BY 4.0.
ami
So, you have downloaded the papers. What do you do with them? Manually read? That’s where ami comes into the picture.
A research paper usually consists of an abstract (the summary), introduction, methods, results, discussion, references, and other miscellaneous sections. Different sections might be relevant based on what the problem at hand is. If, for example, you know you are only looking for the use of certain domain-specific research procedures, “Methods” would be your section of interest. By confining yourself to a specific section can give you better control, as well as make the search transparent and reproducible.
ami, first, takes the papers and sections them. Each paper is cut into abstract, introduction, results and so on. You would then select a section to continue.
Let’s say you pick ‘results’. Reading 100s or 1000s of just the results section is still time-consuming. But ami–search can help! In a sense, ami-search is your automatic annotator. It goes through the section(s) of papers and annotates words/phrases you specify. The set of terms you specify is called ami dictionary. Dictionaries can be hand-made. But we create most dictionaries with the help of Wikidata. Why? The next section of the blog has your answer.
ami can go a step further and display a dashboard with all the annotations with hyperlinks to Wikipedia.
Wikidata
One aspect of the project that is exciting is the use of Wikidata, a structured database with information about anything and everything (well, almost). Wikidata also stores information in different languages.
As mentioned earlier, we use Wikidata to create a set of terms (dictionary) to search the literature. Each term in the dictionary has an associated Wikidata entry, ID, Wikipedia page URL and synonyms in languages other than English.
If let’s say, ami -search annotated the word “antibiotics” in the literature, you might choose a language to display the annotations or read the Wikipedia article about “antibiotics” to comprehend the concepts better.
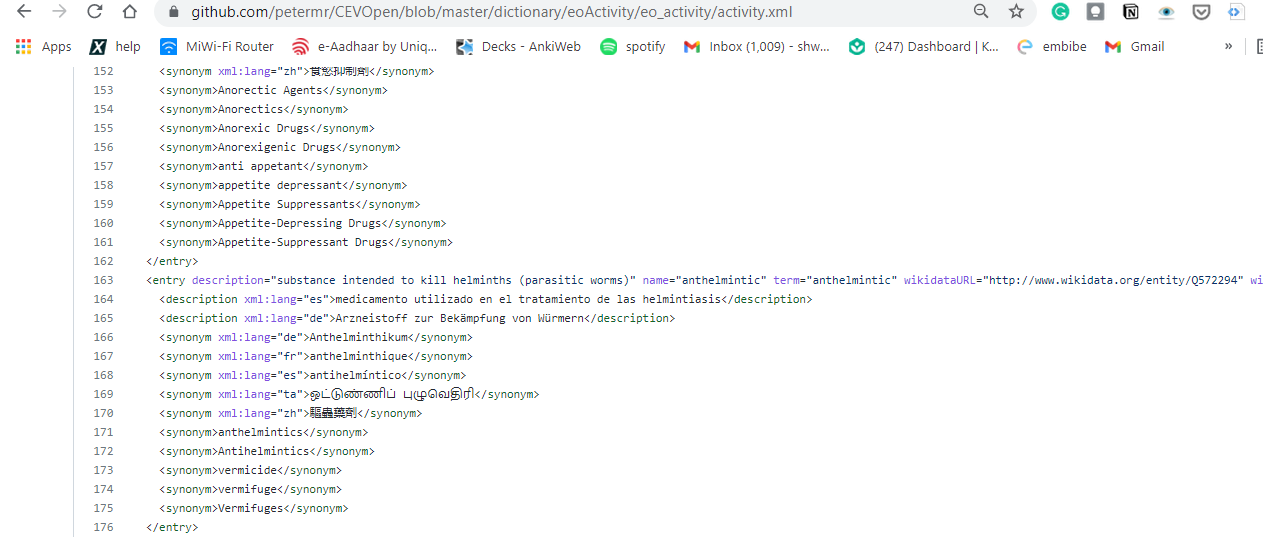
Image: Activity Dictionary from CEVOpen
(Note: The display part of the workflow is still work-in-progress. CEVOpen community is currently working on developing a python version of ami, called pyami. The stable release of pyami would come with the display toolchain.)
How does all of this come together?
We’ve discussed pygetpapers, ami and the role of Wikidata. Let’s see some components of the workflow in action.
In this example, we:
- download a set of papers on “cyclic voltammetry” using
pygetpapers - Extract key phrases from the papers
- Feed selected extracted phrases phrases back to the
pygetpapersquery to streamline and filter searches
https://github.com/ShweataNHegde/snowball/blob/main/snowball_opendiagram_3.ipynb
Summary
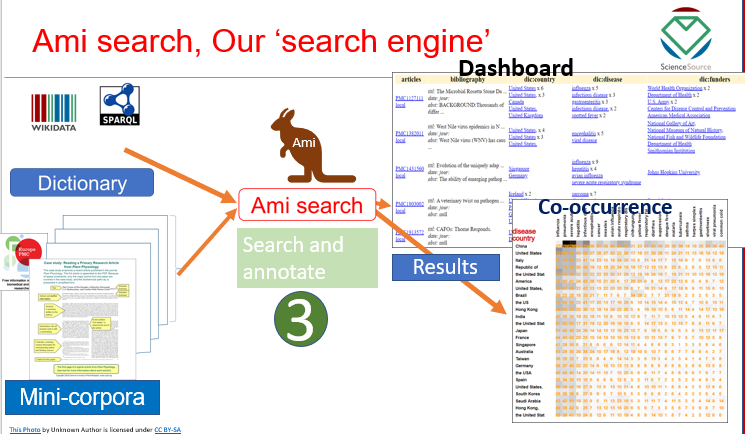
Image: ami workflow, Shweata N. Hegde, CC BY 4.0.
- The use of the
pygetpapers–amisystem empowers the reader. The reader, i.e., chooses which papers to read and decides what you do with them. No publishers control what you see since the analysis is done on your local machine. - The tool has the potential to cut down countless hours researchers spend reading thousands of papers for a literature review.
- The combination of
pygetpapersandpyamican act as an important component of any literature search or even in Citizen Science projects such as the Citizen Science Reader being worked on at CEVOpen.
CEVOpen tools have the potential to help researchers with literature reviews and gain insights about phytochemicals but can be extended to any domains like battery technology, climate change, etc. It’s not far-fetched to imagine citizens using the tool to make sense out of the scientific literature. If you—the citizen—would want to know about what the literature says about climate change after reading about it in the newspaper, you can use our tool to assist in automatically surveying the literature.
We imagine a human-machine symbiosis—rather than a machine optimizing what you see. You can define what goes in the `pyami` dictionary and what papers you analyse. It’s a science search engine with power in the reader’s hands.
In addition, thanks to Wikidata, and the vast ‘structured’ information it holds in a variety of languages, we can annotate the technical terms in these papers with explanations and translations in native languages of your choice.
To reiterate, we—as researchers and citizens—can tackle most, if not, all research questions significantly better if we make use of Text Data Mining tools such as ours. It not only brings down the time spent reviewing literature for answers or directions but also reveals hidden insights that are usually lost when we confine ourselves to a manually reading small subset of the literature.
So, what’s holding you back? All the CEVOpen tools mentioned in the blog are open-source and you can test the waters yourselves! Though Phytochemistry is our focus, we are keen on extending the scope to fields like Electrochemistry, Climate Change, and so on! We already are collaborating with researchers of other fields, and we would love to hear from you!
You can start a conversation by opening a GitHub Issue, here. See you on the other side!
Cite as
Hegde, Shweata N. “Speedy Literature Reviews Using Wikidata and Mining Tools.” Generation Research, 2021. https://doi.org/10.25815/90RZ-4W32.
Wikidata entry: https://www.wikidata.org/wiki/Q108731296



Recent comments